Getting Started¶
In this getting started section you’ll learn more about the concepts behind EuclidesDB and hot to start using it.
Introduction¶
To understand EuclidesDB you need to understand the concepts of its underlying architecture below:
Nowadays, many people are still serving machine learning/deep learning models for requests containing binary data using serialization formats and communication protocols such as JSON+Base64 and HTTP/1.1, which isn’t appropriate for many reasons (a burden for the wire protocol). Serving machine learning models also poses some unique challenges, and although there are many search engines available for feature search, they’re not tight coupled with deep learning frameworks. What happens in practice, is that a lot of different companies end up creating their own systems for model serving, similarity search on the feature space, etc.
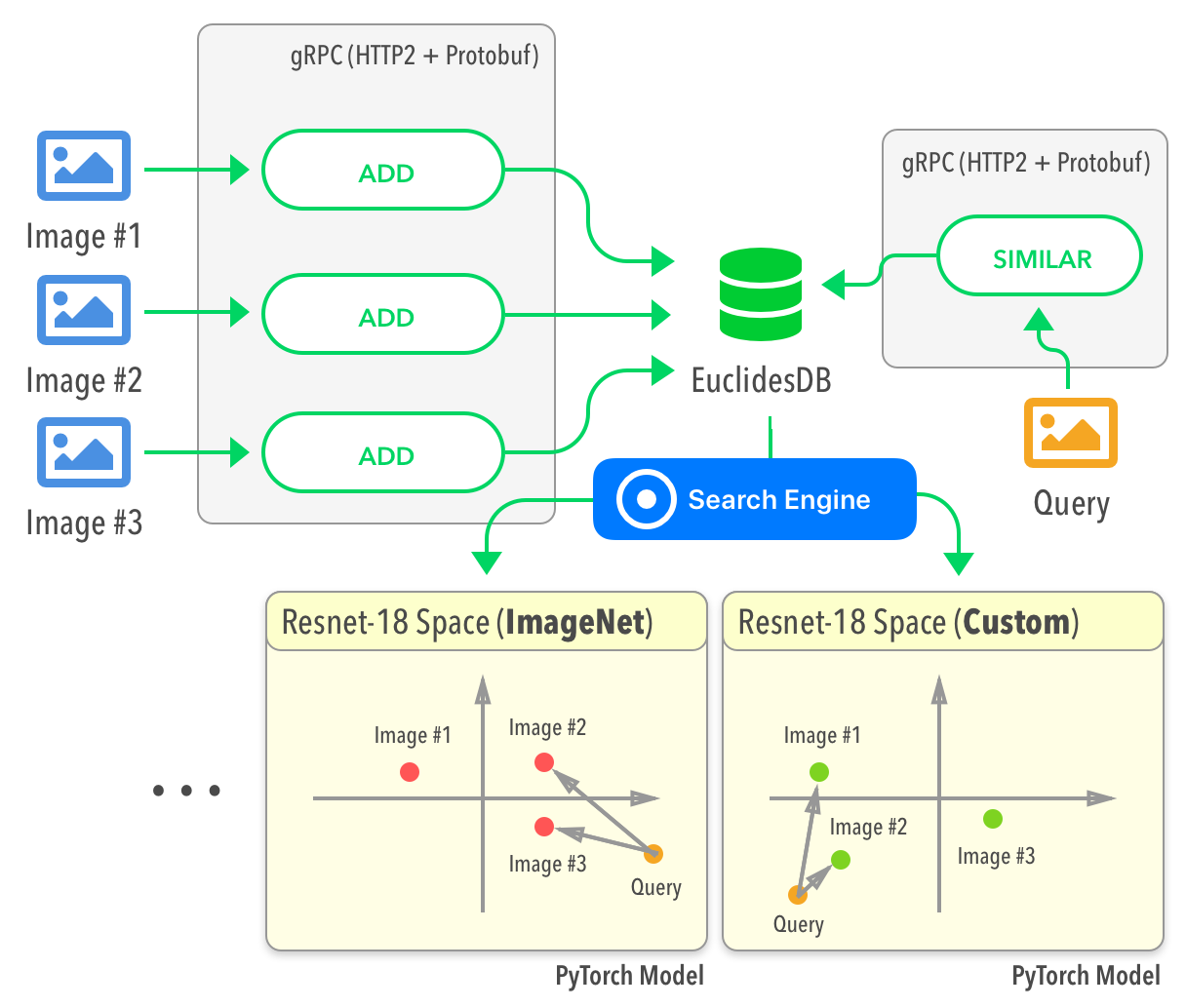
A simple use case that might make the EuclidesDB role clear is the case where you want to do similarity search for, let’s say, fashion industry and you have for instance multiple models trained for each item category (such as shoes, t-shirts, etc), and you want to use different model spaces to index and query different items.
EuclidesDB tries to solve some issues in this context by providing a very simple standalone server that can store, build indexes and serve requests using efficient serialization (protobuf) and protocols (gRPC+HTTP2) with an easy API that can be consumed in many different languages thanks to gRPC. It offers APIs for including new data into its database and quering it later, it also provised a very tight integration with PyTorch, where the libtorch is used as the backend to run traced models, providing a very easy pipeline to integrate new models (written and trained in Python) into the EuclidesDB C++ backend.
Note
For the moment, only binaries with CPU support are available, GPU support will be implemented soon.
Concepts¶
There are some important concepts in EuclidesDB:
- Module/Model: we use the concept Module/Model interchangeably because we use PyTorch modules to represent every computation;
- Model Space: a model space is the space of features that a model generated and that will be consistent within the same model, given that multiple models are supported, you can add a new image in the database only for some particular models or query only some particular model space;
- Search Engine: this is how EuclidesDB index and search for items in the database. EuclidesDB supports a wide range of different indexes that are described in the Search Engine Configuration section;
When you add a new image or other kind of data (we’re expanding the support for other kind of items) into the database, you also specify which model should be used to index this data. Then this data is forwarded into these specified models and their features are saved into a local key-value database to be used later on the construction of a querying index.
The same happens when you query for similar items on a model space, you make a request with a new image and specify on which model spaces you want to find similar items, and the similar items for each model space will be returned together with their relevance.